







實現海量數據存儲
實現海量數據的分布式存儲,隨著數據量的增長,根據需要實現線性擴容
經緯大數據智能分析平臺集成了Hadoop、Spark、SolrCloud等平臺上的大數據分析基礎平臺,涵蓋底層大規模分布式計算、底層計算調度、上層各種應用分析的一站式需求平臺,能夠將互聯網所能呈現的所有“結構化和非結構化”數據加載到平臺,進行可視化圖表展現和深度分析。
經緯大數據智能分析平臺集成了Hadoop、Spark、SolrCloud等平臺上的大數據分析基礎平臺,涵蓋底層大規模分布式計算、底層計算調度、上層各種應用分析的一站式需求平臺,能夠將互聯網所能呈現的所有“結構化和非結構化”數據加載到平臺,進行可視化圖表展現和深度分析。提供了從采集、建模、存儲、分析到智能決策的全流程數據驅動解決方案,幫助企業驅動業務決策和智能應用。

同時該平臺也集成了自主研發的語義分析系統和情感分析系統,全端采集和歷史產生的所有數據,為企業建立完整數據倉庫,深度挖掘數據價值。結合深度學習技術能夠快速的從海量數據(境外facebook/twitter、境內全網數據)里面發現熱點話題與熱門事件,更能夠快速的進行人物畫像分析及大屏指揮系統等多維度、多指標的交叉分析能力,全面支撐業務團隊的日常數據分析需求,驅動業務決策,為品牌維護和競品分析提供有力的技術保證。
支持私有化部署,積累客戶歷史數據資產,確保數據安全,確保性能的前提下,硬件成本低。

實現海量數據的分布式存儲,隨著數據量的增長,根據需要實現線性擴容

具備在短時間內對海量數據進行去重、并行計算等多業務處理能力,并隨著數據的增長,能根據需要實現對計算性能的線性提升

通過與SparkStreaming等開源技術對接,目前平臺已經集成Kmeans、協同過濾、關聯挖掘、熱榜算法、邏輯回歸、隨機森林、統計分析,以及深度機器學習,視頻文本分析等多種算法模型。這些算法經過大量的項目大規模及復雜的數據場景演練,其有效性、算法能力和計算規模都得到了很好的實踐檢驗

平臺可以讓客戶通過“低成本、好操作、易復制”的方式快速建立企業級及政務大數據分析應用,極大的簡化大數據分析的過程和操作難度,讓人人都能夠通過平臺快速從數據中獲得智慧決策的樂趣




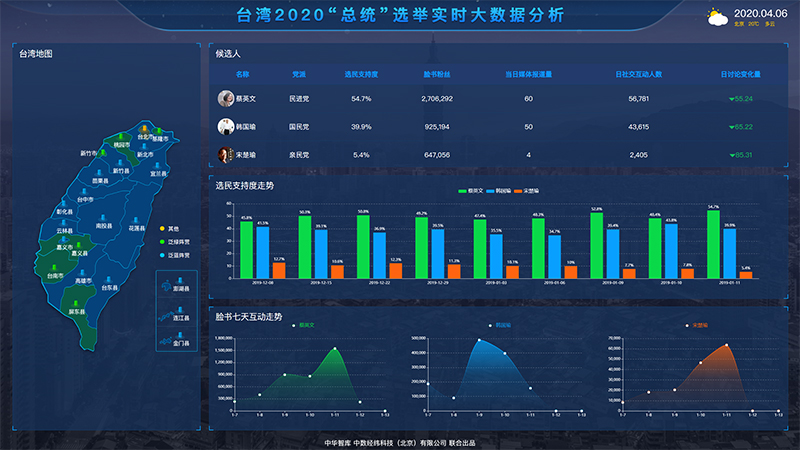
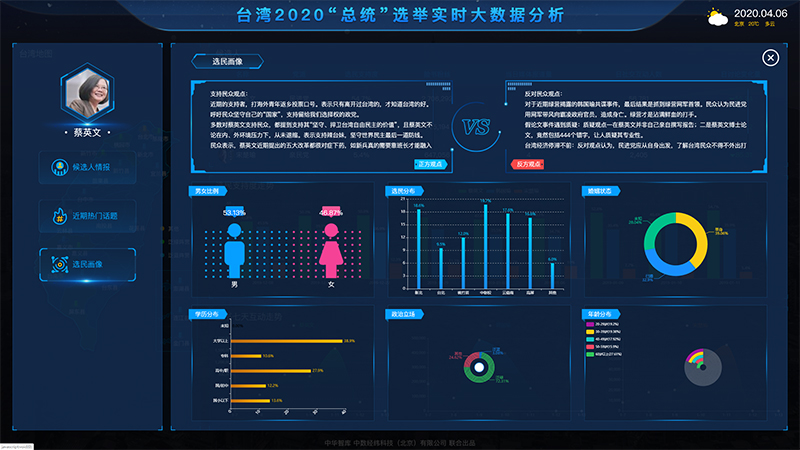
通過對海量數據進行歸類統計及相關計算,可以快速形成各類大屏指揮系統,能夠快速從大屏幕上了解到例如突發事件等熱點信息,從而對相關決策起到輔助性作用,該大屏指揮系統具備如下特點:
A、顯示效果清晰自然,分辨率高,動態效果流暢
B、能實現單屏顯、組合顯、整屏顯等功能
C、可以實現實時的監控畫面顯示等多種應用處理和集成功能,完全滿足信息集中顯示、大數據量處理、實時準確顯示的需要

平臺可廣泛應用于交通、環保、食品安全、環境、農業、旅游、醫療、醫藥等重要行業的大數據基礎設施建設領域,也可應用于企業和政務大數據分析領域中,可為用戶提供自主可控、安全可靠、智能高效于一體的解決方案和產品。
郵箱:market@chinadata8.com
電話:+86-10-88430890(北京)
網站公安備案號:11010802036023

關注微信公眾號

android客戶端

IOS客戶端